我们在上一篇文章中对推荐系统中的召回算法进行了简单梳理。从本章开始,我们会花3章的篇幅来详细介绍推荐系统召回算法的具体思路和实现细节。上一章中我们提到了可以按照算法复杂度将召回算法分为3类,接下来的3章我们按照这个分类来介绍召回算法,我们会分别讲解规则策略召回算法、基础召回算法、高阶召回算法。本章我们介绍规则策略召回算法。
7.1 基于热门的召回
7.2 基于物品标签的召回
7.2.1 物品关联物品的召回
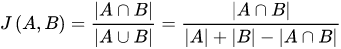
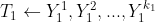
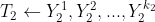
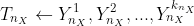
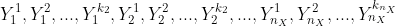
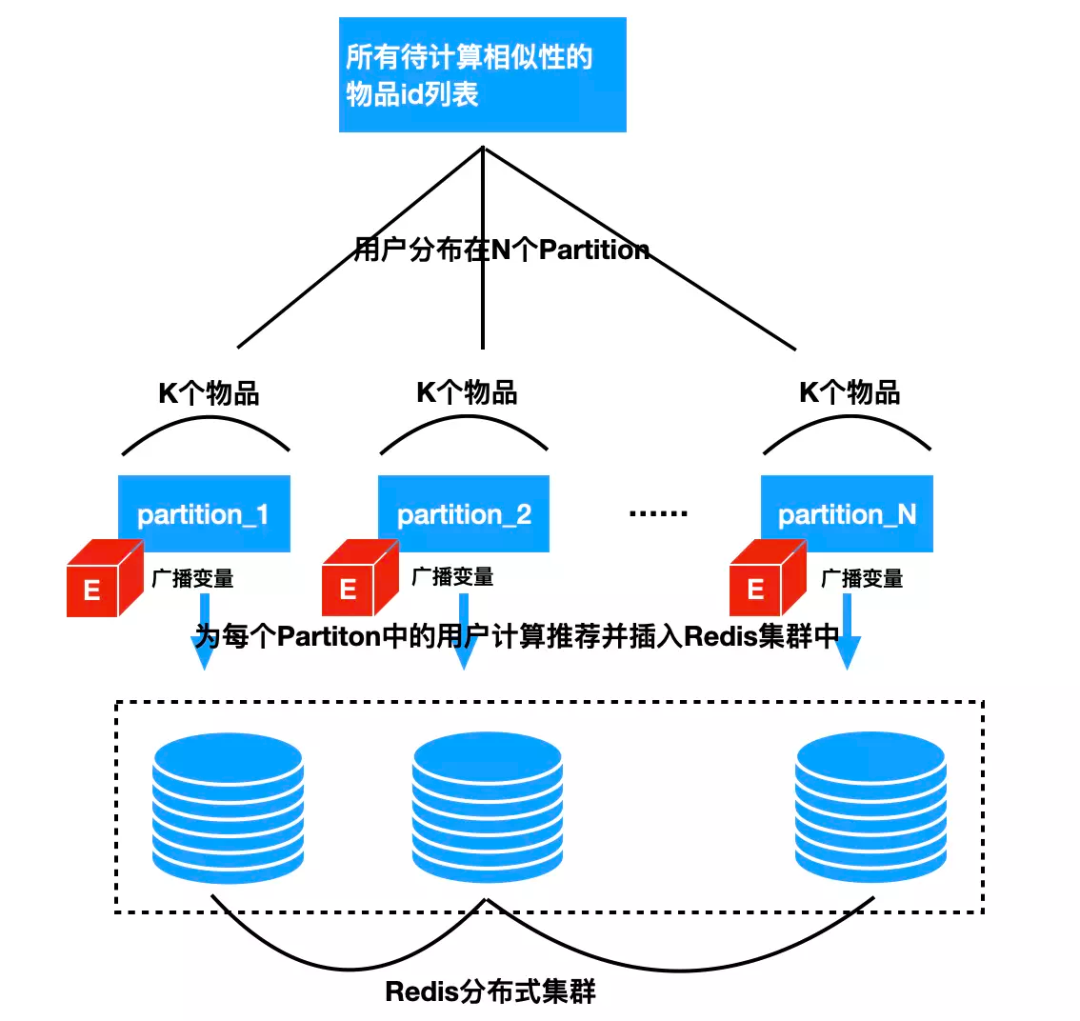
7.2.2 个性化召回
7.2.2.1 利用种子物品召回
7.2.2.2 利用用户兴趣标签召回
 )比例的时间,那么权重就是w(比如一个视频5分钟,你看了2分钟,那么w=2/5=0.4)。如果视频A本身的标签也有权重,那么用户对标签的权重就是这两个权重的乘积,利用公式说明如下:
)比例的时间,那么权重就是w(比如一个视频5分钟,你看了2分钟,那么w=2/5=0.4)。如果视频A本身的标签也有权重,那么用户对标签的权重就是这两个权重的乘积,利用公式说明如下: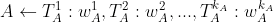
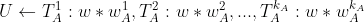
7.3 基于用户画像的召回
7.3.1 基于用户自然属性的召回
7.3.2 基于用户社会属性的召回
7.3.3 基于用户业务属性的召回
7.3.4 基于用户设备属性的召回
7.4 基于地域的召回
7.5 基于时间的召回
总结
本文来自微信公众号【数据与智能】,未经许可谢绝二次转载至其他网站,如需转载请联系微信liuq4360。