我们在上一篇文章中介绍了规则策略召回算法,这类方法非常简单,只需要利用一些业务经验和基础的统计计算就可以实现了。本节我们来讲解一些基础的召回算法,这类算法要么是非常经典的方法,要么是需要利用一些机器学习知识的,相比上一章的方法要更复杂一点,不过也不难,只要懂一些基础的机器学习和数学知识就可以很好地理解算法原理。
具体来说,本章我们会讲解关联规则召回、聚类召回、朴素贝叶斯召回、协同过滤召回、矩阵分解召回等5类召回算法。我们会讲清楚具体的算法原理及工程实现的核心思想,读者可以结合自己公司的业务情况思考一下这些算法怎么用到具体的业务中。
8.1 关联规则召回算法
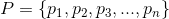 是所有物品的集合(对于家乐福超市来说,就是所有的商品集合)。关联规则一般表示为 的形式,其中是的子集,并且
是所有物品的集合(对于家乐福超市来说,就是所有的商品集合)。关联规则一般表示为 的形式,其中是的子集,并且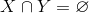 。关联规则表示如果在用户的购物篮(用户一次购买的物品的集合称为一个购物篮,通常用户购买的物品会放到一个篮子里,所以叫做购物篮)中,那么用户有很大概率同时购买了 。
。关联规则表示如果在用户的购物篮(用户一次购买的物品的集合称为一个购物篮,通常用户购买的物品会放到一个篮子里,所以叫做购物篮)中,那么用户有很大概率同时购买了 。
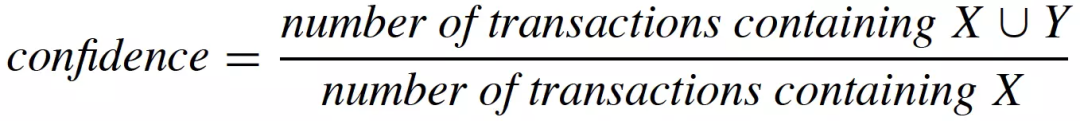
挖掘出所有满足一定支持度和置信度(支持度和置信度大于某个常数)的关联规则; 从1中所有的关联规则中筛选出所有满足的关联规则; 为用户生成召回候选集,具体计算如下:
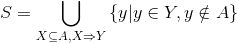
8.2 聚类召回算法
k-means算法的步骤:
input:N个样本点,每个样本点是一个n维向量,每一维代表一个特征。最大迭代次数M。
(1)从N个样本点中随机选择k个点作为中心点,尽量保证这k个距离相对远一点
(2)针对每个非中心点,计算他们离k个中心点的距离(欧氏距离)并将该点归类到距离最近的中心点
(3)针对每个中心点,基于归类到该中心点的所有点,计算它们新的中心(可以用各个点的坐标轴的平均值来估计),进而获得k个新的中心点
(4)重复上述步骤(2)、(3),直到迭代次数达到M或者前后两次中心点变化不大(可以计算前后两次中心点变化的平均绝对误差,比如绝对误差小于某个很小的阈值就认为变化不大)
8.2.1 基于用户聚类的召回
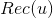 是给用户u的召回,是用户所在的聚类,
是给用户u的召回,是用户所在的聚类,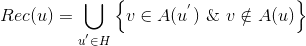
8.2.2 基于物品聚类的召回
是给用户的推荐,是用户的历史操作行为集合,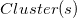 是物品所在的聚类。
是物品所在的聚类。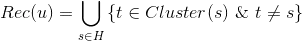
8.3 朴素贝叶斯召回算法
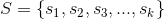 ,所有用户对物品的评分构成用户行为矩阵,该矩阵的-元素记为,即是用户对物品的评分,取值为评分集合中的某个元素。下面我们来讲解怎么利用贝叶斯公式来为用户召回。
,所有用户对物品的评分构成用户行为矩阵,该矩阵的-元素记为,即是用户对物品的评分,取值为评分集合中的某个元素。下面我们来讲解怎么利用贝叶斯公式来为用户召回。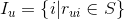 。现在我们需要预测用户对未评分的物品的评分(
。现在我们需要预测用户对未评分的物品的评分(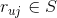 )。我们可以将这个过程理解为在用户已经有评分记录的条件下,用户对新物品的评分取集合中某个值的条件概率:
)。我们可以将这个过程理解为在用户已经有评分记录的条件下,用户对新物品的评分取集合中某个值的条件概率: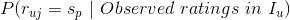
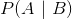 ,表示的是在事件发生的情况下事件发生的概率,由著名的贝叶斯定理,条件概率可以通过如下公式来计算:
,表示的是在事件发生的情况下事件发生的概率,由著名的贝叶斯定理,条件概率可以通过如下公式来计算:
 ,基于贝叶斯公式,我们有
,基于贝叶斯公式,我们有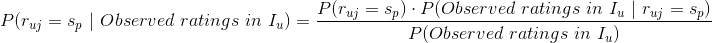 的值最大,这个最大的值就可以作为用户对未评分的物品的评分(=)。我们注意到上式中右边的分母的值与具体的无关,因此右边分子的值的大小才最终决定公式左边的值的相对大小,基于该观察,我们可以将上式记为:
的值最大,这个最大的值就可以作为用户对未评分的物品的评分(=)。我们注意到上式中右边的分母的值与具体的无关,因此右边分子的值的大小才最终决定公式左边的值的相对大小,基于该观察,我们可以将上式记为: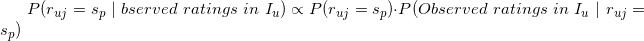
估计 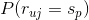
其实是的先验概率,我们可以用对物品评分为的用户的比例来估计该值,即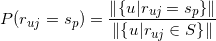
估计 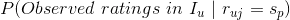
,我们需要做一个朴素的假设,即条件无关性假设:用户所有的评分是独立无关的,也就是不同的评分之间是没有关联的,互不影响(该假设就是该算法叫做朴素贝叶斯的由来)。实际上,同一用户对不同物品评分可能是有一定关联的,在这里做这个假设是为了计算方便,在实际使用朴素贝叶斯做召回时效果还是很不错的,泛化能力也可以。就可以用如下公式来估计了: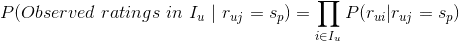
 可用所有对物品评分为的用户中对物品评分为的比例来估计。即
可用所有对物品评分为的用户中对物品评分为的比例来估计。即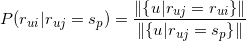
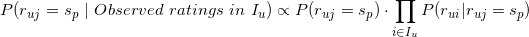 ,使得取值最大的p对应的作为的估计值,即
,使得取值最大的p对应的作为的估计值,即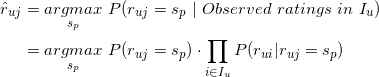
8.4 协同过滤召回算法
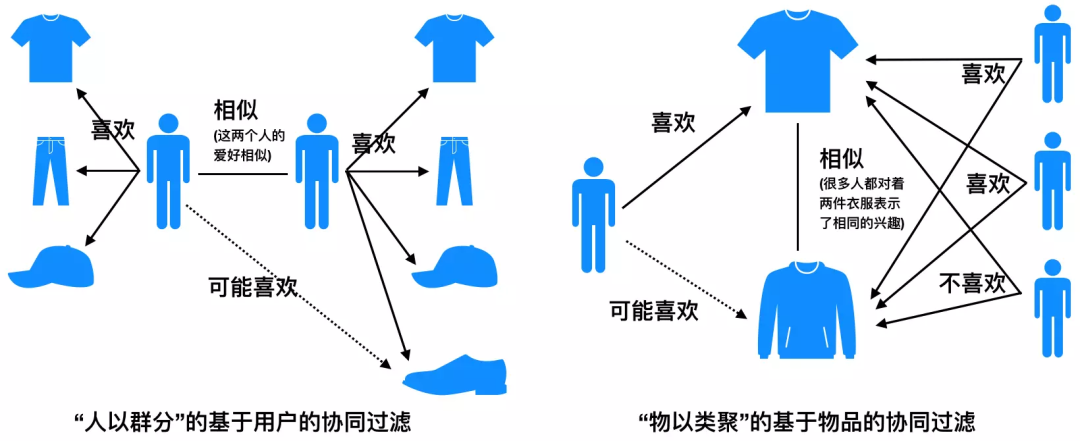

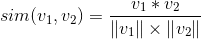
8.4.1 基于用户的协同过滤
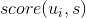 是用户对物品s的喜好度(对于隐式反馈为1,而对于非隐式反馈,该值为用户对物品的评分),
是用户对物品s的喜好度(对于隐式反馈为1,而对于非隐式反馈,该值为用户对物品的评分), 是用户与用户u的相似度。
是用户与用户u的相似度。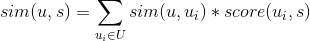
8.4.2 基于物品的协同过滤
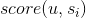 是用户u对物品的喜好度,
是用户u对物品的喜好度, 是物品与s的相似度。
是物品与s的相似度。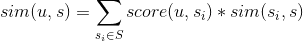
8.5 矩阵分解召回算法
8.5.1 矩阵分解召回算法的核心思想
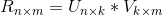
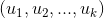 乘以物品特征矩阵,最终得到用户对每个物品的评分
乘以物品特征矩阵,最终得到用户对每个物品的评分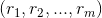 。
。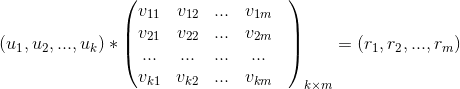 后,从该评分中过滤掉用户已经操作过的物品,针对剩下的物品得分做降序排列取topN作为该用户的召回结果。
后,从该评分中过滤掉用户已经操作过的物品,针对剩下的物品得分做降序排列取topN作为该用户的召回结果。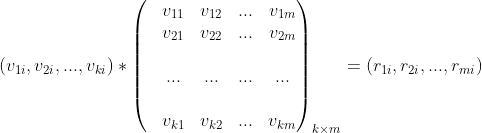
8.5.2 矩阵分解召回算法的原理
 ,通过矩阵分解将用户和物品嵌入k维隐式特征空间的向量分别为:
,通过矩阵分解将用户和物品嵌入k维隐式特征空间的向量分别为:
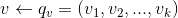
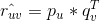 ,真实值与预测值之间的误差为
,真实值与预测值之间的误差为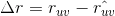 。如果预测得越准,那么越小,针对所有用户评分过的对,如果我们可以保证这些误差之和尽量小,那么有理由认为我们的预测是精准的。
。如果预测得越准,那么越小,针对所有用户评分过的对,如果我们可以保证这些误差之和尽量小,那么有理由认为我们的预测是精准的。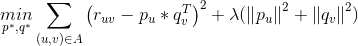
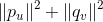 是正则项,避免模型过拟合。通过求解该最优化问题,我们就可以获得用户和物品的特征嵌入(用户的特征嵌入,就是上一节中用户特征矩阵的行向量,同理,物品的特征嵌入就是物品特征矩阵的列向量),有了特征嵌入,基于8.5.1节的思路,就可以为用户进行个性化召回了,也可以为物品进行物品关联物品的召回了。
是正则项,避免模型过拟合。通过求解该最优化问题,我们就可以获得用户和物品的特征嵌入(用户的特征嵌入,就是上一节中用户特征矩阵的行向量,同理,物品的特征嵌入就是物品特征矩阵的列向量),有了特征嵌入,基于8.5.1节的思路,就可以为用户进行个性化召回了,也可以为物品进行物品关联物品的召回了。8.5.3 矩阵分解召回算法的求解方法
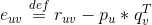

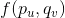 对求偏导数,具体计算如下:
对求偏导数,具体计算如下: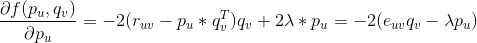
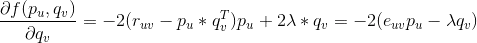
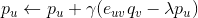
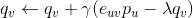
总结
参考文献
A Bayesian model for collaborative filtering Collaborative filtering with the simple Bayesian classifier Item-based collaborative filtering recommendation algorithms item-based top-n recommendation algorithms Collaborative filtering for implicit feedback datasets Large-Scale Parallel Collaborative Filtering for the Netflix Prize Collaborative Filtering for Implicit Feedback Datasets 本文来自微信公众号【数据与智能】,未经许可谢绝二次转载至其他网站,如需转载请联系微信liuq4360。