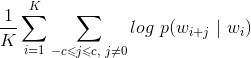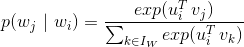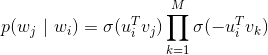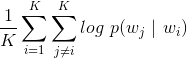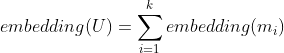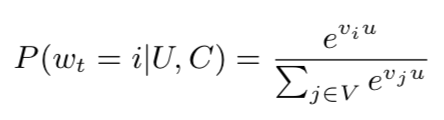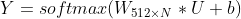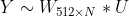「从零入门推荐系统」09:召回算法之嵌入召回算法和深度学习召回算法
智能技术 数据技术
数据与智能 2022-12-26 179
我们在上一篇文章中介绍了5种基础的召回算法,这5种召回算法原理简单,工程实现容易,非常实用。本章我们会讲解两类更复杂的召回算法,一类是嵌入方法召回,另一类是深度学习召回。
由于本系列文章是入门文章,不会讲太多太复杂的算法,我们会拿几个最有价值的方法介绍给大家。更现代、更复杂的的召回算法,我们会在本章提一下,但是不会深入介绍,读者自己可以去了解相关文献和材料。话不多说,下面我们先来讲解嵌入方法召回。所谓嵌入方法召回,是指将用户或者物品嵌入到一个低维的稠密向量空间,然后基于向量的相似度来计算用户与物品(或者物品与物品)的相似度来进行召回的方法。我们在上面一章中介绍的矩阵分解算法其实就是一种简单的嵌入,用户特征向量和物品特征向量分别是用户和物品的嵌入。没有太多印象或者想回顾一下的读者可以参考上一章8.5节的介绍。本节我们主要介绍2016年微软提出的item2vec嵌入方法,这个算法是对Google著名的Word2Vec算法的推广。毫不夸张地说,正是Google的Word2Vec开启了嵌入方法在各类业务场景(推荐、搜索、广告等)应用的高潮。为了让大家可以更好地理解item2vec,我们有必要先来介绍一下Word2Vec的基本原理。Word2Vec算法是Google工程师在2013年提出的一种浅层神经网络嵌入方法,主要目的是将词嵌入到低维向量空间,可以捕获词的上下文之间的关系。Word2Vec方法自从被提出后在各类NLP任务中获得了非常好的效果,并被拓展到包括推荐系统等在内的多种业务场景中。下面对该算法的原理做简单介绍。后面要讲到的item2vec嵌入方法及很多其它嵌入方法都是从该算法吸收灵感而提出的。Word2vec方法可以保证语义之间的相关性,这里举两个简单的例子:假设我们有一个大的中文语料库,基于该语料库,我们利用Word2Vce算法获得了字和词组的嵌入表示,那么一个训练得足够好的模型,可以得到如下结论:- embedding(男) - embedding(女)
 embedding(雄性) - embedding(雌性)
embedding(雄性) - embedding(雌性) - embedding(中国) - embedding(北京)
 embedding(美国) - embedding(华盛顿)
embedding(美国) - embedding(华盛顿)
上面的减号是两个向量对应分量的相减,比如(4,5) - (1,3) = (3,2),  是约等于号,说明左右两边的向量相似(在欧式空间中距离非常近)。从这里例子中,读者应该能够看到Word2Vec模型的强大和神奇之处了吧!Word2Vec有两种实现方法:CBOW和Skip-Gram,CBOW是基于前后的单词预测中间单词的出现概率,而Skip-Gram是基于中间单词来预测它前后单词的出现概率,具体如下面图1。实践经验表面Skip-Gram效果更好,所以我们这里也只讲解Skip-Gram算法。假设
是约等于号,说明左右两边的向量相似(在欧式空间中距离非常近)。从这里例子中,读者应该能够看到Word2Vec模型的强大和神奇之处了吧!Word2Vec有两种实现方法:CBOW和Skip-Gram,CBOW是基于前后的单词预测中间单词的出现概率,而Skip-Gram是基于中间单词来预测它前后单词的出现概率,具体如下面图1。实践经验表面Skip-Gram效果更好,所以我们这里也只讲解Skip-Gram算法。假设 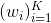 是有限词汇表
是有限词汇表 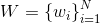 中的一个词序列。Word2Vec方法将求解词嵌入问题转化为求解下面的目标函数的极大值问题:其中,c是词
中的一个词序列。Word2Vec方法将求解词嵌入问题转化为求解下面的目标函数的极大值问题:其中,c是词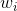 的上下文(附近的词)窗口的大小,
的上下文(附近的词)窗口的大小,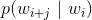 是下面的softmax函数:
是下面的softmax函数: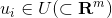 和
和  分别是词
分别是词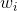 的目标(target)和上下文(context)嵌入表示,这里
的目标(target)和上下文(context)嵌入表示,这里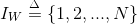 ,参数m是嵌入空间的维数。为了让读者更好地理解
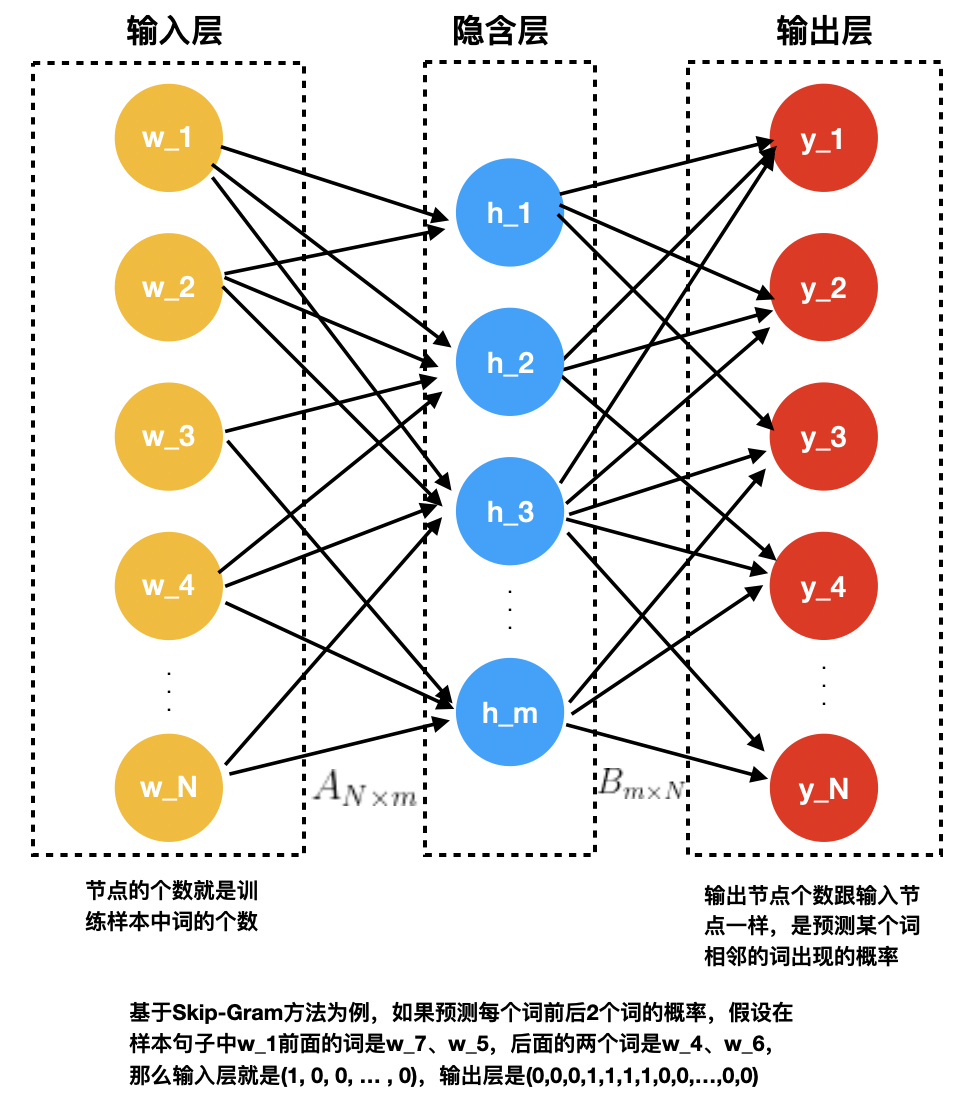
,参数m是嵌入空间的维数。为了让读者更好地理解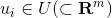 和 到底是什么,我们可以将Word2Vec看成是一个浅层的神经网络模型(参考下面图2),那么上面的就是从输入层到隐藏层的矩阵
和 到底是什么,我们可以将Word2Vec看成是一个浅层的神经网络模型(参考下面图2),那么上面的就是从输入层到隐藏层的矩阵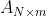 的行向量,是从隐藏层到输出层的矩阵
的行向量,是从隐藏层到输出层的矩阵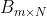 的列向量,那么最终的就是单词的嵌入向量。对比公式1和图2的神经网络结构,我们可以很容易知道,上述神经网络解释中的隐藏层的激活函数是ReLU函数,输出层激活函数是softmax函数。相信通过上面的类比,读者可以更好地理解Word2Vec模型了。那么怎么求解公式1中的最优化模型呢?直接优化公式1的目标函数是非常困难的,因为求
的列向量,那么最终的就是单词的嵌入向量。对比公式1和图2的神经网络结构,我们可以很容易知道,上述神经网络解释中的隐藏层的激活函数是ReLU函数,输出层激活函数是softmax函数。相信通过上面的类比,读者可以更好地理解Word2Vec模型了。那么怎么求解公式1中的最优化模型呢?直接优化公式1的目标函数是非常困难的,因为求 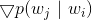 计算量太大,是词库大小N的线性函数,一般N是百万级别以上。我们可以通过负采样(Negative Sampling)来减少计算量,具体来说,就是用如下的公式来代替上面的softmax函数。这里
计算量太大,是词库大小N的线性函数,一般N是百万级别以上。我们可以通过负采样(Negative Sampling)来减少计算量,具体来说,就是用如下的公式来代替上面的softmax函数。这里  是logistic函数,M是采样的负样本(这里负样本是指抽样的词
是logistic函数,M是采样的负样本(这里负样本是指抽样的词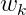 不在词目标
不在词目标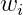 的上下文中)数量。最终可以用随机梯度下降算法来训练公式1中的模型,估计出U 、V。读者可以阅读参考文献1、2、3、4对Word2Vec进行深入学习和了解。有很多开源的软件有Word2Vec的实现,比如Spark、gensim、TensorFlow、Pytorch等。微软在2016年基于Word2Vec提出了item2vec(参考文献5),基于用户的操作行为,通过将物品嵌入到低维向量空间的方式来计算物品之间的相似度,最后进行关联推荐。下面对该方法进行简单介绍。我们可以将用户操作过的所有物品看成词序列,这里每个物品就相当于一个词,只是这里用户操作过的物品是一个集合,不是一个有序序列。虽然用户操作物品是有时间顺序的,但是物品之间不像词序列是有上下文关系的(一般不存在一个用户看了电影A之后才能看电影B,但是在句子中,词的搭配是有序关系的),因此这里当成集合会更合适。所以,我们需要对Word2Vec的目标函数进行适当修改,最终我们可以将item2vec的目标函数定义为这里不存在固定的窗口大小了,窗口的大小就是用户操作过的物品集合的大小(这个假设是想说明用户行为序列中任何两个物品之间都是有一定的关联关系的)。而其他部分跟Word2Vec的优化目标函数一模一样。最终用向量
的上下文中)数量。最终可以用随机梯度下降算法来训练公式1中的模型,估计出U 、V。读者可以阅读参考文献1、2、3、4对Word2Vec进行深入学习和了解。有很多开源的软件有Word2Vec的实现,比如Spark、gensim、TensorFlow、Pytorch等。微软在2016年基于Word2Vec提出了item2vec(参考文献5),基于用户的操作行为,通过将物品嵌入到低维向量空间的方式来计算物品之间的相似度,最后进行关联推荐。下面对该方法进行简单介绍。我们可以将用户操作过的所有物品看成词序列,这里每个物品就相当于一个词,只是这里用户操作过的物品是一个集合,不是一个有序序列。虽然用户操作物品是有时间顺序的,但是物品之间不像词序列是有上下文关系的(一般不存在一个用户看了电影A之后才能看电影B,但是在句子中,词的搭配是有序关系的),因此这里当成集合会更合适。所以,我们需要对Word2Vec的目标函数进行适当修改,最终我们可以将item2vec的目标函数定义为这里不存在固定的窗口大小了,窗口的大小就是用户操作过的物品集合的大小(这个假设是想说明用户行为序列中任何两个物品之间都是有一定的关联关系的)。而其他部分跟Word2Vec的优化目标函数一模一样。最终用向量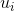 (参考9.1.1节中对
(参考9.1.1节中对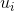 的定义)来表示物品的嵌入,用cosine余弦相似度来计算两个物品的相似度。也可以用、
的定义)来表示物品的嵌入,用cosine余弦相似度来计算两个物品的相似度。也可以用、 、
、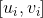 (
(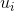 和
和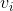 拼接在一起的向量)来表示物品的嵌入。作者之前在做视频推荐系统的时候,也采用了item2vec算法来对视频进行嵌入(作者采用的是gensim框架来训练item2vec的,见参考文献6),并用于视频的相似推荐中,点击率效果比原来的基于矩阵分解的嵌入有较大幅度的提升。上面介绍完了item2vec的基本原理,下面我们来说明一下怎么利用item2vec来进行召回。我们在之前的章节中提到过召回可以分为物品关联物品召回和个性化召回,下面我们就按照这两种召回范式来说明。物品关联物品召回非常简单。只要用item2vec获得了每个物品的嵌入向量表示,那么就可以为每个物品通过向量相似(如cosine余弦相似度)计算与它最相似的topN的物品作为召回就可以了。那怎么计算这个topN相似呢?特别是当物品数量很大时,计算代价是很大的(计算复杂度是
拼接在一起的向量)来表示物品的嵌入。作者之前在做视频推荐系统的时候,也采用了item2vec算法来对视频进行嵌入(作者采用的是gensim框架来训练item2vec的,见参考文献6),并用于视频的相似推荐中,点击率效果比原来的基于矩阵分解的嵌入有较大幅度的提升。上面介绍完了item2vec的基本原理,下面我们来说明一下怎么利用item2vec来进行召回。我们在之前的章节中提到过召回可以分为物品关联物品召回和个性化召回,下面我们就按照这两种召回范式来说明。物品关联物品召回非常简单。只要用item2vec获得了每个物品的嵌入向量表示,那么就可以为每个物品通过向量相似(如cosine余弦相似度)计算与它最相似的topN的物品作为召回就可以了。那怎么计算这个topN相似呢?特别是当物品数量很大时,计算代价是很大的(计算复杂度是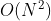 ,这里N是物品的数量)。下面我来说介绍两种计算topN相似度的方法。如果你熟悉Spark等分布式计算平台,那么就可以利用Spark的分布式计算能力来实现topN的计算,具体思路参考第七章“召回算法之规则策略方法”中7.2.1节的介绍,这里不再赘述。这个方法最大的问题是只能批处理做离线召回,计算好后将召回结果存到Redis等数据库中供业务使用。下面我们讲到的方法2是可以实时召回的,在业务需要的时候进行召回,下面我们来讲解。这个方法是采用算法的手段(比如局部敏感哈希)高效实时地从海量向量中找到跟某个向量最相似的topN向量,细节读者可以查看参考文献7,这里我们不展开讲解。这类方法一般是近似计算,精度有一定损耗,但是可以保证在毫秒级就可以计算出topN相似。可以说是用精度来换时间的一种做法,这种方法在企业级推荐系统中是非常实用的一种做法。大家也不用自己去实现这类算法了,目前在工业界有成熟的开源工具。这类工具中最早、最出名的一个是Facebook开源的Faiss框架(见参考文献8)。另外还有一个基于Faiss进行二次封装的框架milvus也非常出名(见参考文献9、10),这个框架可以通过Restful API的方式进行查询,使用起来非常方便。类似的框架还有很多,这里不一一列举了。上面一小节介绍了物品关联物品召回,那么怎么计算个性化召回呢?这里提供两种思路,具体说明如下:一般在信息流推荐中,用户最近操作过的物品是非常重要的,代表了用户的短期兴趣。那么可以将用户最近操作过(代表了用户有兴趣)的几个物品作为种子物品,就可以采用前面一节提到的物品关联物品召回的方式来为该用户进行个性化召回。如果我们可以记录用户的行为序列(
,这里N是物品的数量)。下面我来说介绍两种计算topN相似度的方法。如果你熟悉Spark等分布式计算平台,那么就可以利用Spark的分布式计算能力来实现topN的计算,具体思路参考第七章“召回算法之规则策略方法”中7.2.1节的介绍,这里不再赘述。这个方法最大的问题是只能批处理做离线召回,计算好后将召回结果存到Redis等数据库中供业务使用。下面我们讲到的方法2是可以实时召回的,在业务需要的时候进行召回,下面我们来讲解。这个方法是采用算法的手段(比如局部敏感哈希)高效实时地从海量向量中找到跟某个向量最相似的topN向量,细节读者可以查看参考文献7,这里我们不展开讲解。这类方法一般是近似计算,精度有一定损耗,但是可以保证在毫秒级就可以计算出topN相似。可以说是用精度来换时间的一种做法,这种方法在企业级推荐系统中是非常实用的一种做法。大家也不用自己去实现这类算法了,目前在工业界有成熟的开源工具。这类工具中最早、最出名的一个是Facebook开源的Faiss框架(见参考文献8)。另外还有一个基于Faiss进行二次封装的框架milvus也非常出名(见参考文献9、10),这个框架可以通过Restful API的方式进行查询,使用起来非常方便。类似的框架还有很多,这里不一一列举了。上面一小节介绍了物品关联物品召回,那么怎么计算个性化召回呢?这里提供两种思路,具体说明如下:一般在信息流推荐中,用户最近操作过的物品是非常重要的,代表了用户的短期兴趣。那么可以将用户最近操作过(代表了用户有兴趣)的几个物品作为种子物品,就可以采用前面一节提到的物品关联物品召回的方式来为该用户进行个性化召回。如果我们可以记录用户的行为序列(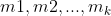 ), 用户行为序列中的每个物品我们都可以利用item2vec算法获得嵌入表示,那么用户的嵌入表示可以通过如下公式获得:注意,上面的求和可以是向量对应元素求平均或者对应元素取最大值,这里举例说明一下,方便读者更好理解。假设我们有两个向量(1,3,4)和(2,5,3),那么按照对应元素求平均和对应元素取最大值对这两个向量进行计算的结果分别是(1,8/3,7/3)和(2,5,4)。由于嵌入的空间是高维空间(一般嵌入向量是几十维或者几百维),高维空间是非常稀疏的。工程实践上,利用上面逐元素对向量求平均或者取最大值的方式也可以非常好地区分两个用户。这里区分的意思是:如果两个用户的行为序列不一样,那么他们通过上面方式计算获得的嵌入也不一样,两个用户行为序列越近似,获得的嵌入向量的欧氏距离也越小。上面讲完了基于item2vec方法进行召回的例子。基于其他嵌入方法进行推荐召回的例子还有很多,感兴趣的读者可以阅读参考文献11、12、13,这几个参考文献中还提到了一些解决推荐系统冷启动的思路,读者可以参考一下。另外,基于Bert等更现代的嵌入方法在推荐系统中也有广泛的应用,读者可以自行学习。上面我们讲到的item2vec嵌入方法也算是一种浅层的神经网络模型,上面也对item2vec的神经网络模型进行了解释了,相信读者也理解了其中的思想。我们在本节要介绍一个在业界大名鼎鼎的利用深度学习进行召回的模型,那就是YouTube深度学习推荐模型(见参考文献14),这篇文章作者认为是最有工程价值的一篇深度学习推荐论文,在深度学习推荐系统中有奠基性作用,希望读者可以好好学习一下。下面我们就对这篇论文中的深度学习算法进行召回的思想和价值进行说明。
), 用户行为序列中的每个物品我们都可以利用item2vec算法获得嵌入表示,那么用户的嵌入表示可以通过如下公式获得:注意,上面的求和可以是向量对应元素求平均或者对应元素取最大值,这里举例说明一下,方便读者更好理解。假设我们有两个向量(1,3,4)和(2,5,3),那么按照对应元素求平均和对应元素取最大值对这两个向量进行计算的结果分别是(1,8/3,7/3)和(2,5,4)。由于嵌入的空间是高维空间(一般嵌入向量是几十维或者几百维),高维空间是非常稀疏的。工程实践上,利用上面逐元素对向量求平均或者取最大值的方式也可以非常好地区分两个用户。这里区分的意思是:如果两个用户的行为序列不一样,那么他们通过上面方式计算获得的嵌入也不一样,两个用户行为序列越近似,获得的嵌入向量的欧氏距离也越小。上面讲完了基于item2vec方法进行召回的例子。基于其他嵌入方法进行推荐召回的例子还有很多,感兴趣的读者可以阅读参考文献11、12、13,这几个参考文献中还提到了一些解决推荐系统冷启动的思路,读者可以参考一下。另外,基于Bert等更现代的嵌入方法在推荐系统中也有广泛的应用,读者可以自行学习。上面我们讲到的item2vec嵌入方法也算是一种浅层的神经网络模型,上面也对item2vec的神经网络模型进行了解释了,相信读者也理解了其中的思想。我们在本节要介绍一个在业界大名鼎鼎的利用深度学习进行召回的模型,那就是YouTube深度学习推荐模型(见参考文献14),这篇文章作者认为是最有工程价值的一篇深度学习推荐论文,在深度学习推荐系统中有奠基性作用,希望读者可以好好学习一下。下面我们就对这篇论文中的深度学习算法进行召回的思想和价值进行说明。9.2.1 YouTube深度学习召回算法原理介绍
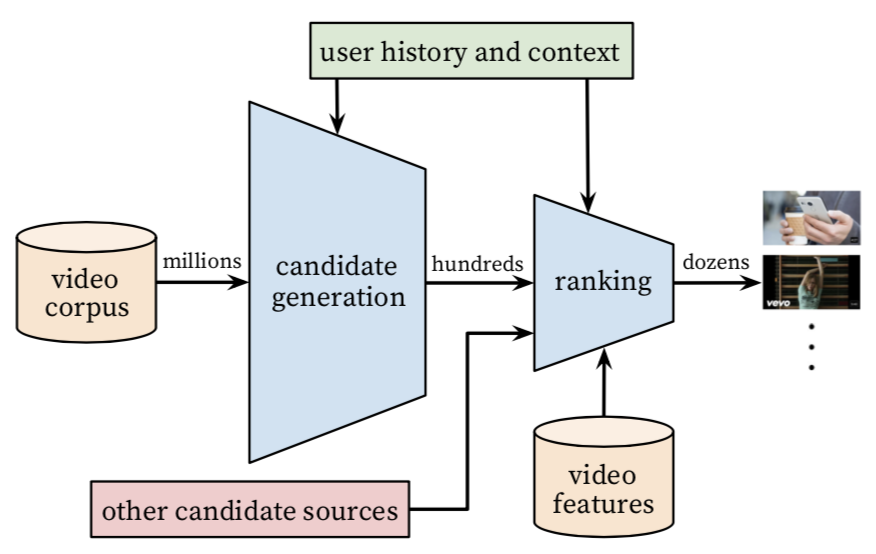
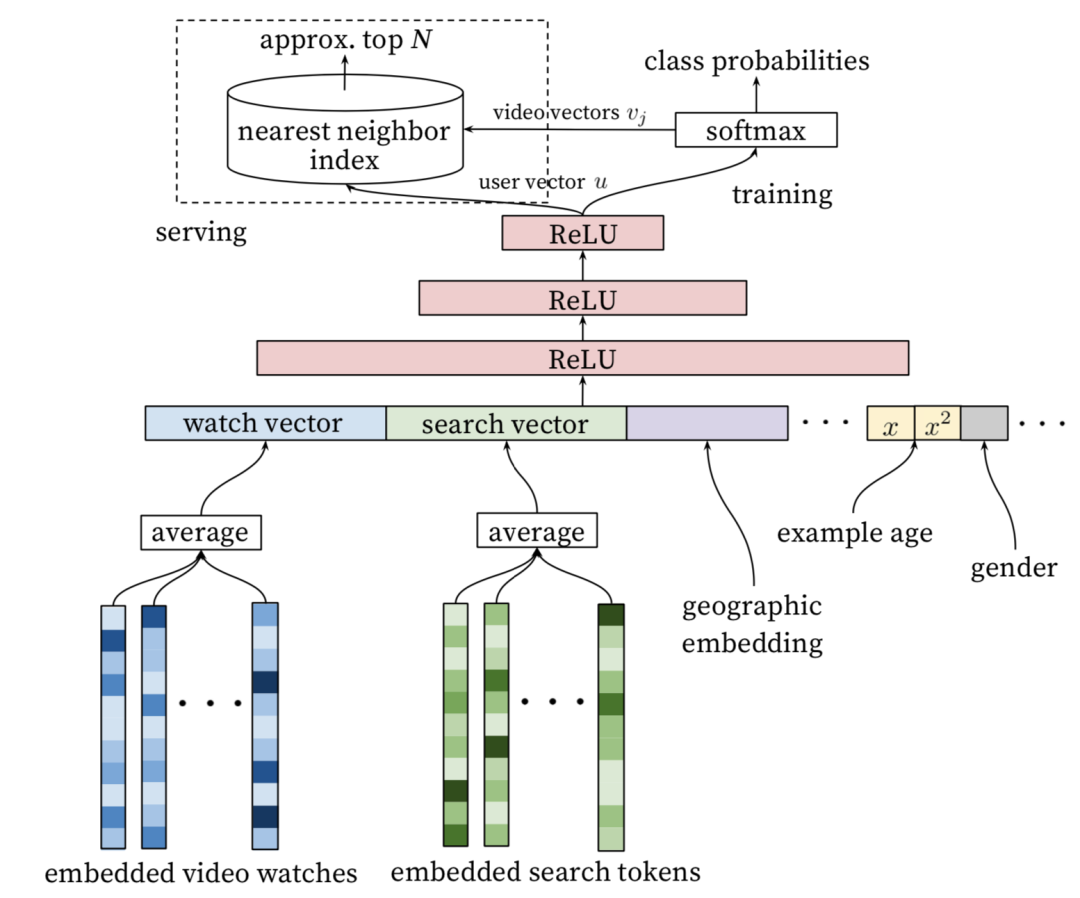
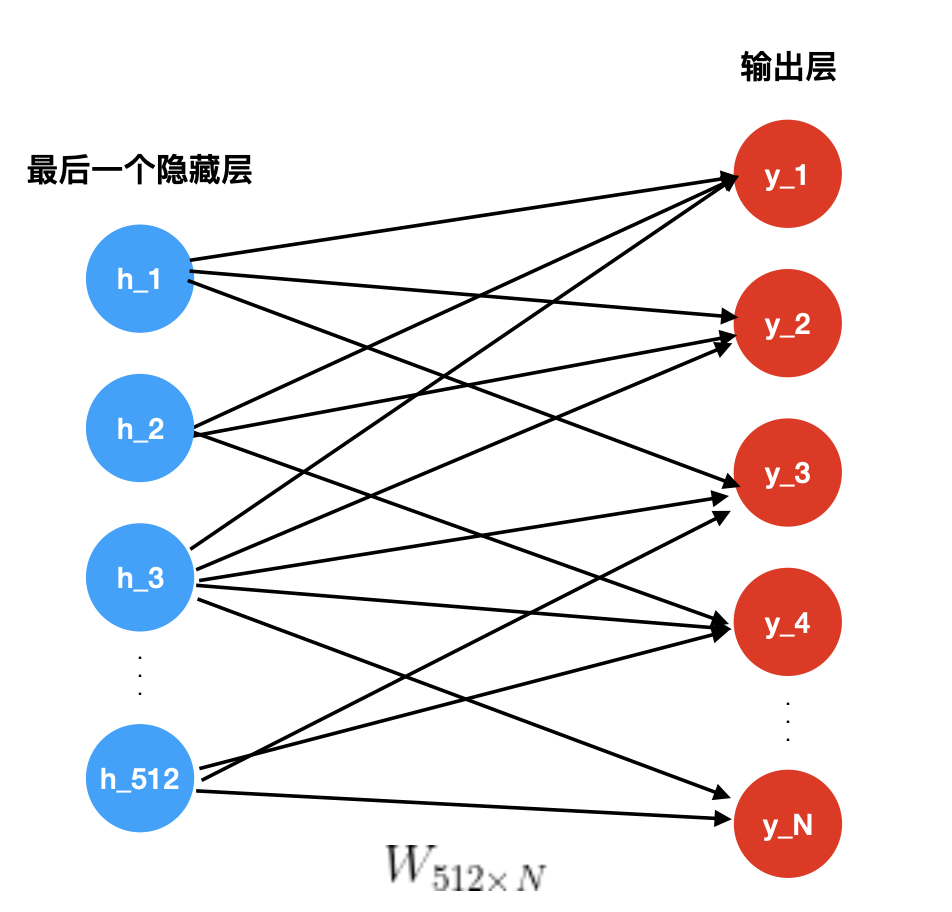
YouTube深度学习推荐系统发表于2016年,应用于YouTube上的视频推荐。这篇文章按照工业级推荐系统的架构将整个推荐流程分为两个阶段:候选集生成(召回)和候选集排序(排序)(见下面图3),这也是业内最主流的做法,我们在前面的文章中也讲过。本节我们主要讲解召回阶段的深度学习实现原理。候选集生成阶段根据用户在YouTube上的行为为用户生成几百个候选视频,候选集视频期望尽量匹配用户可能的兴趣偏好。YouTube这篇文章通过将推荐问题看成一个多分类问题(类别的数量等于视频个数),基于用户过去观看记录预测用户下一个要观看的视频的类别。利用深度学习(MLP)来进行建模,将用户和视频嵌入同一个低维向量空间(所以这篇文章其实也算是一种嵌入方法),通过softmax激活函数来预测用户在时间点 t 观看视频 i 的的概率。具体预测概率公式如下:其中u、v分别是用户和视频的嵌入向量。U是用户集,C是上下文,V是视频集。该方法通过一个(深度学习)模型来一次性学习出用户和视频的嵌入向量。由于用户在YouTube的显示反馈较少,该模型采用隐式反馈数据,这样可以用于模型训练的数据量会大很多,这刚好适合深度学习这种强依赖数据量的算法系统。为了更快地训练深度学习多分类问题,该模型采用了负采样机制(重要性加权的候选视频集抽样)提升训练速度。最终通过最小化交叉熵损失函数(cross-entropy loss)求得模型参数。通过负采样可以将整个模型训练加速上百倍。候选集生成阶段的深度学习模型结构参加下面图4。首先将用户的行为记录按照item2vec的思路嵌入到低维空间中,将用户的所有点击过的视频的嵌入向量求平均,获得用户播放行为的综合嵌入表示(即下图的watch vector)。同样的道理,可以将用户的搜索词做嵌入,获得用户综合的搜素行为嵌入向量(即下图的search vector)。同时跟用户的其他非视频播放特征(地理位置、性别等)拼接为最终灌入深度学习模型的输入向量,再通过三层全连接的ReLU层,最终通过输出层(输出层的维度就是视频个数)的softmax激活函数获得输出,利用交叉熵损失函数来训练模型最终求解最优的深度学习模型。上面讲完了模型的核心思路,思路是非常简单的。但是在具体工程实现上,这边论文提供了一个非常巧妙的、高效地进行召回的实现方案,这就是下一小节要讲解的内容。上面介绍了YouTube深度学习召回算法的原理,下面我们来讲解一下候选集生成阶段是怎么来筛选出候选集的,这一块在论文中没有讲的很清楚,我们在这里会详细讲解实现细节,希望给读者提供一个非常好的工程实现思路。图4中的深度学习模型的最上一层ReLU层是512维的,这一层可以认为是一个嵌入表示,表示的是用户的嵌入向量。那么怎么获得视频的嵌入向量呢?先说结论,视频的嵌入向量就是最后一个ReLU隐藏层到输出层的矩阵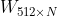 的列向量,下面我们来解释一下为什么是这样的。我们先将图4中最上一层ReLU层到输出层的结构重新画一下(见下面图5),让大家可以看的更清楚。图5中 U = (h_1 , h_2 , h_3 , ... , h_512) 是用户的嵌入向量。那么基于图4的神经网络,预测用户U的输出可以用下面公式计算:上式中的b是最后一个隐藏层到输出层的偏置项。Y 是输出层的概率(N维向量),那么给用户U的召回结果就是Y向量中概率最大的topK的视频。图5:视频嵌入向量是的列向量从softmax的计算公式
的列向量,下面我们来解释一下为什么是这样的。我们先将图4中最上一层ReLU层到输出层的结构重新画一下(见下面图5),让大家可以看的更清楚。图5中 U = (h_1 , h_2 , h_3 , ... , h_512) 是用户的嵌入向量。那么基于图4的神经网络,预测用户U的输出可以用下面公式计算:上式中的b是最后一个隐藏层到输出层的偏置项。Y 是输出层的概率(N维向量),那么给用户U的召回结果就是Y向量中概率最大的topK的视频。图5:视频嵌入向量是的列向量从softmax的计算公式 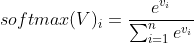 (这里是计算向量
(这里是计算向量 第i个分量的softmax)可以看到,如果某个分量的值大,那么对应分量的softmax值也大,这里可以说softmax函数是对应分量的单调递增函数。那么根据公式2,Y相应分量的大小等价于
第i个分量的softmax)可以看到,如果某个分量的值大,那么对应分量的softmax值也大,这里可以说softmax函数是对应分量的单调递增函数。那么根据公式2,Y相应分量的大小等价于 的大小(b参数的加入不会对softmax函数的单调性产生任何影响),我们可以记为:那么很明显,如果向量的相似度用向量的内积计算,那么与U最相似的视频嵌入向量(即的列向量)对应的预测点击概率最大,所以,基于公式2来计算topK召回的过程就等价于利用U向量在所有视频嵌入向量(即的列向量)中求最相似的topK的过程。这就是图4左上角用最近邻来获取用户的召回的理论解释。下面我们来简单说说这么做的价值是什么?如果按照图4中的深度学习模型,在进行推断时,需要将特征灌入模型,然后计算输出层的点击概率预测。由于模型比较复杂,计算速度会比较慢,影响线上服务性能。如果按照我们上面等价的方法,从视频向量中找最相似的topK是更好的做法,因为速度快(前面也提到,我们有最近邻搜索的工具,可以在毫秒级获得用户向量最相似的topK视频向量)。最后我们再提一下,根据前面的介绍,如果YouTube深度学习模型训练好后,我们可以获得从隐藏层最后一层到输出层的矩阵,这个矩阵的列向量表示的是视频的嵌入向量,有了视频的嵌入向量,那么我们就可以计算视频关联视频的相似召回了。具体怎么计算视频相似召回,我们在前面的item2vec介绍部分已经做过讲解,这里就不赘述。上面我们介绍完了YouTube深度学习召回算法的核心原理和在召回服务时的处理策略,我们可以看到,YouTube推荐系统的工程化思路是非常有创意的。YouTube这篇深度学习推荐系统论文中有非常多的有创意的工程实现技巧,希望读者可以阅读原文进一步学习,这里就不详细介绍了。到此为止我们介绍完了嵌入方法召回和YouTube深度学习召回的核心原理和工程技巧,希望读者对本章讲解的内容有比较全面的理解和掌握。嵌入方法和深度学习召回算法实现方案非常多,本章只简单讲解了item2vec和YouTube深度学习推荐系统召回这两个最经典的例子。希望读者从这两个例子中可以学习到复杂召回算法的核心思想和精妙之处。更高阶的召回算法读者可以自己去查阅相关资料。关于召回算法的介绍我们就到这里了,希望读者对过去3章介绍的规则策略的召回算法、基础召回算法、高阶召回算法的基本原理和工程实现有比较好的了解和掌握。从下一章开始,我们会讲解推荐系统的排序算法。
的大小(b参数的加入不会对softmax函数的单调性产生任何影响),我们可以记为:那么很明显,如果向量的相似度用向量的内积计算,那么与U最相似的视频嵌入向量(即的列向量)对应的预测点击概率最大,所以,基于公式2来计算topK召回的过程就等价于利用U向量在所有视频嵌入向量(即的列向量)中求最相似的topK的过程。这就是图4左上角用最近邻来获取用户的召回的理论解释。下面我们来简单说说这么做的价值是什么?如果按照图4中的深度学习模型,在进行推断时,需要将特征灌入模型,然后计算输出层的点击概率预测。由于模型比较复杂,计算速度会比较慢,影响线上服务性能。如果按照我们上面等价的方法,从视频向量中找最相似的topK是更好的做法,因为速度快(前面也提到,我们有最近邻搜索的工具,可以在毫秒级获得用户向量最相似的topK视频向量)。最后我们再提一下,根据前面的介绍,如果YouTube深度学习模型训练好后,我们可以获得从隐藏层最后一层到输出层的矩阵,这个矩阵的列向量表示的是视频的嵌入向量,有了视频的嵌入向量,那么我们就可以计算视频关联视频的相似召回了。具体怎么计算视频相似召回,我们在前面的item2vec介绍部分已经做过讲解,这里就不赘述。上面我们介绍完了YouTube深度学习召回算法的核心原理和在召回服务时的处理策略,我们可以看到,YouTube推荐系统的工程化思路是非常有创意的。YouTube这篇深度学习推荐系统论文中有非常多的有创意的工程实现技巧,希望读者可以阅读原文进一步学习,这里就不详细介绍了。到此为止我们介绍完了嵌入方法召回和YouTube深度学习召回的核心原理和工程技巧,希望读者对本章讲解的内容有比较全面的理解和掌握。嵌入方法和深度学习召回算法实现方案非常多,本章只简单讲解了item2vec和YouTube深度学习推荐系统召回这两个最经典的例子。希望读者从这两个例子中可以学习到复杂召回算法的核心思想和精妙之处。更高阶的召回算法读者可以自己去查阅相关资料。关于召回算法的介绍我们就到这里了,希望读者对过去3章介绍的规则策略的召回算法、基础召回算法、高阶召回算法的基本原理和工程实现有比较好的了解和掌握。从下一章开始,我们会讲解推荐系统的排序算法。- [Word2Vec] Distributed Representations of Words and Phrases and their Compositionality (Google 2013)
- [Word2Vec] Efficient Estimation of Word Representations in Vector Space (Google 2013)
- [Word2Vec] Word2vec Parameter Learning Explained (UMich 2016)
- Network–Efficient Distributed Word2vec Training System for Large Vocabularies
- [2016 微软] Item2Vec- Neural Item Embedding for Collaborative Filtering
- https://github.com/RaRe-Technologies/gensim
- [2008] Locality-sensitive hashing for finding nearest neighbors
- https://github.com/facebookresearch/faiss
- https://github.com/milvus-io/milvus
- [2018 阿里] Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
- [2018 阿里] Learning and Transferring IDs Representation in E-commerce
- [2017 Criteo] Specializing Joint Representations for the task of Product Recommendation
- [YouTube 2016] Deep Neural Networks for YouTube Recommendations
本文来自微信公众号【数据与智能】,未经许可谢绝二次转载至其他网站,如需转载请联系微信liuq4360。
本文为专栏作者授权科易网发表,版权归原作者所有。文章系作者个人观点,不代表科易网立场,转载请联系原作者。如有任何疑问,请联系ky@1633.com。

相关推荐
超声靶向造影的用途
超声靶向造影的用途
超声靶向造影是一种医学检查方法,其通过注射一种含有组织特异性靶标分子的超声造影剂,使造影剂聚集在靶器官或组织处,从而增强声学信号,实现定性和定量分析活体组织细胞、分子水平的生理及病理变化过程或局部靶向治疗的目的。
关键词:超声造影,卵巢癌,拟态
聚乳酸(PLA)产业研究动态
聚乳酸(PLA)产业研究动态
以聚乳酸(PLA)、竹粉为主要原料,通过双螺杆挤出工艺制备竹粉—聚乳酸(PLA)复合材料,研究了不同目数的竹粉及马兰酸酐接枝前后竹粉对竹粉—聚乳酸(PLA)复合材料的物理力学性能及相容性的影响。
关键词:双螺杆挤出,PLA,工艺制备,竹粉
氨法脱硫硫技术专家推荐
氨法脱硫硫技术专家推荐
氨法脱硫是一种高效的湿法脱硫方式,它采用氨作为脱硫剂,通过气液相反应来实现对烟气中二氧化硫的净化。具体原理是将液氨与水混合配制成为一定浓度的氨水,然后将氨水引入脱硫塔中,与锅炉烟气中的二氧化硫发生反应,生成亚硫酸铵。再通过氧化风机不断注入空气,将亚硫酸铵氧化成硫酸铵,从而实现对烟气中二氧化硫的净化。
关键词:离子对,复合电极,氨法脱硫
弯拉弹性模量专利申请
弯拉弹性模量专利申请
通过对几种贫混凝土:碾压贫混凝土、振捣式贫混凝土、掺粉煤灰贫混凝土的弯拉强度与弯拉弹性模量的试验,研究分析了贫混凝土基层材料弯拉弹性模量的特性。试验采用小梁试件进行三分点加荷的方式,测定3kN至50%极限荷载处的割线模量,用跨中挠度公式反算求得。
关键词:混凝土基层,弹性模量,掺粉煤灰
找乳酸盐类/血液技术开发服务商
找乳酸盐类/血液技术开发服务商
乳酸盐在血液中扮演着重要的角色。首先,乳酸盐在运动过程中可能影响局部和中央的血流量。当运动开始时,乳酸盐释放到血液循环中,能够促进血管舒张,提高血液含氧量,确保氧气能够有效地输送到活跃的肌肉中,以满足运动状态下组织的各种需求。
关键词:动物血,血乳酸,乳酸
脑源性神经营养因子(BDNF)产学研合作资源
脑源性神经营养因子(BDNF)产学研合作资源
脑源性神经营养因子(brain-derived neurotrophic factor,BDNF)是1982年Barde等首先在猪脑中发现的一种具有神经营养作用的蛋白质。这是一种在大脑内合成的蛋白质,对神经元的存活、分化以及正常功能的维持起到重要作用。它广泛分布于中枢神经系统,特别是在海马和皮质的含量最高。
关键词:BDNF,阿尔茨海默,脑源性神经营养因子
敏感蛋白产业研究动态
敏感蛋白产业研究动态
测定30个不同麦芽样品的总氮、可溶性氮、库值、总酚含量以及对应麦汁敏感蛋白及敏感多酚含量,并对结果进行相关性分析发现,麦汁敏感蛋白含量与麦芽可溶性氮呈显著正相关(r=0.686,p0.01),麦汁敏感多酚含量与麦芽总酚呈显著正相关(r=0.646,p0.01),表明麦芽可溶性氮与总酚指标可初步用于评价麦汁中敏感蛋白与敏感多酚含量;
关键词:麦芽,总酚含量,多酚,总氮
桥博技术哪里有?
桥博技术哪里有?
在铁路桥梁建设中,单箱单室预应力混凝土连续箱梁较为普遍。在进行设计计算时,一般是把三维空间桥梁结构进行简化,在纵向和横向分别对桥梁进行平面杆系计算。
关键词:三维空间,预应力混凝土,铁路桥梁,连续箱梁