我们在上一篇文章中介绍了5种最基础的、基于规则策略的排序算法,那些算法是在没有足够的用户行为数据的情况下不得已才采用的方法,一旦我们有了足够多的行为数据,那么我们就可以采用更加客观、科学的机器学习排序算法了。
12.1 logistics回归排序算法
12.1.1 logistics回归的算法原理


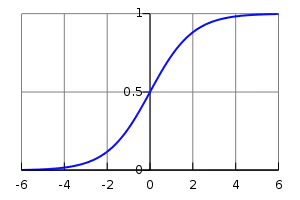
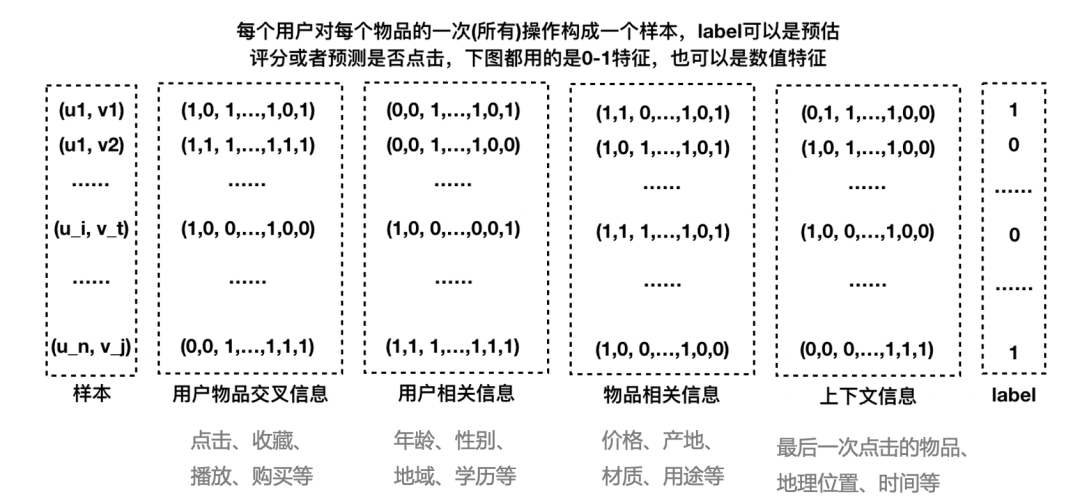
12.1.2 logistics回归的特点
12.1.3 logistics回归的工程实现
12.1.4 logistics回归在业界的应用
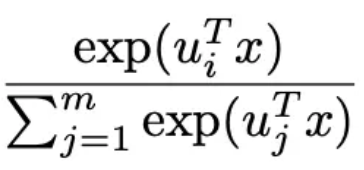 部分),见下面的公式3。当m=1时就是普通的logistics回归模型,当m大时,预估的会越准,但是这时参数也越多,需要更多的训练样本、更长的训练时间才能训练出有效果保证的模型。
部分),见下面的公式3。当m=1时就是普通的logistics回归模型,当m大时,预估的会越准,但是这时参数也越多,需要更多的训练样本、更长的训练时间才能训练出有效果保证的模型。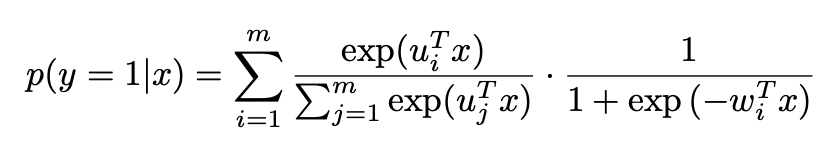
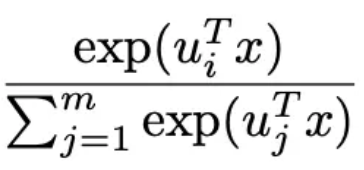 类似于注意力机制的注意力参数。关于这个模型的细节介绍,大家可以阅读参考文献3,这里不展开说明了。
类似于注意力机制的注意力参数。关于这个模型的细节介绍,大家可以阅读参考文献3,这里不展开说明了。12.2 FM排序算法
12.2.1 FM的算法原理

 训练不充分而不准确,最终影响模型的效果。特别是对于推荐、广告等这类数据非常稀疏的业务场景来说(这些场景的最大特点就是特征非常稀疏,推荐是由于标的物是海量的,每个用户只对很少的标的物有操作,因此很稀疏,广告是由于很少有用户去点击广告,点击率很低,导致收集的数据量很少,因此也很稀疏),很多特征之间交叉是没有(或者没有足够多)训练数据支撑的,因此无法很好地学习出对应的模型参数。因此上述整合二阶两两交叉特征的模型并未在工业界得到广泛采用。
训练不充分而不准确,最终影响模型的效果。特别是对于推荐、广告等这类数据非常稀疏的业务场景来说(这些场景的最大特点就是特征非常稀疏,推荐是由于标的物是海量的,每个用户只对很少的标的物有操作,因此很稀疏,广告是由于很少有用户去点击广告,点击率很低,导致收集的数据量很少,因此也很稀疏),很多特征之间交叉是没有(或者没有足够多)训练数据支撑的,因此无法很好地学习出对应的模型参数。因此上述整合二阶两两交叉特征的模型并未在工业界得到广泛采用。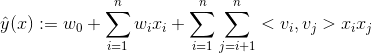
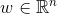 、
、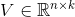 。
。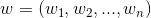 ,是n维向量。
,是n维向量。
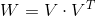 (Cholesky decomposition)。这说明,FM这种通过分解的方式基本可以拟合任意的二阶交叉特征,只要分解的维度k足够大(首先,
(Cholesky decomposition)。这说明,FM这种通过分解的方式基本可以拟合任意的二阶交叉特征,只要分解的维度k足够大(首先,12.2.2 FM的参数估计
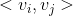 和
和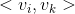 共用一个相同的向量
共用一个相同的向量 ,而整合两两二阶交叉的线性模型的系数个数为
,而整合两两二阶交叉的线性模型的系数个数为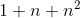 。分解机的系数个数是n的线性函数,而整合交叉项的线性模型系数个数是n的指数函数,当n非常大时,训练分解机模型在存储空间及迭代速度上是非常有优势的。
。分解机的系数个数是n的线性函数,而整合交叉项的线性模型系数个数是n的指数函数,当n非常大时,训练分解机模型在存储空间及迭代速度上是非常有优势的。12.2.3 FM的计算复杂度
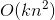 。但是我们可以通过适当的公式变换与数学计算,将模型复杂度降低到
。但是我们可以通过适当的公式变换与数学计算,将模型复杂度降低到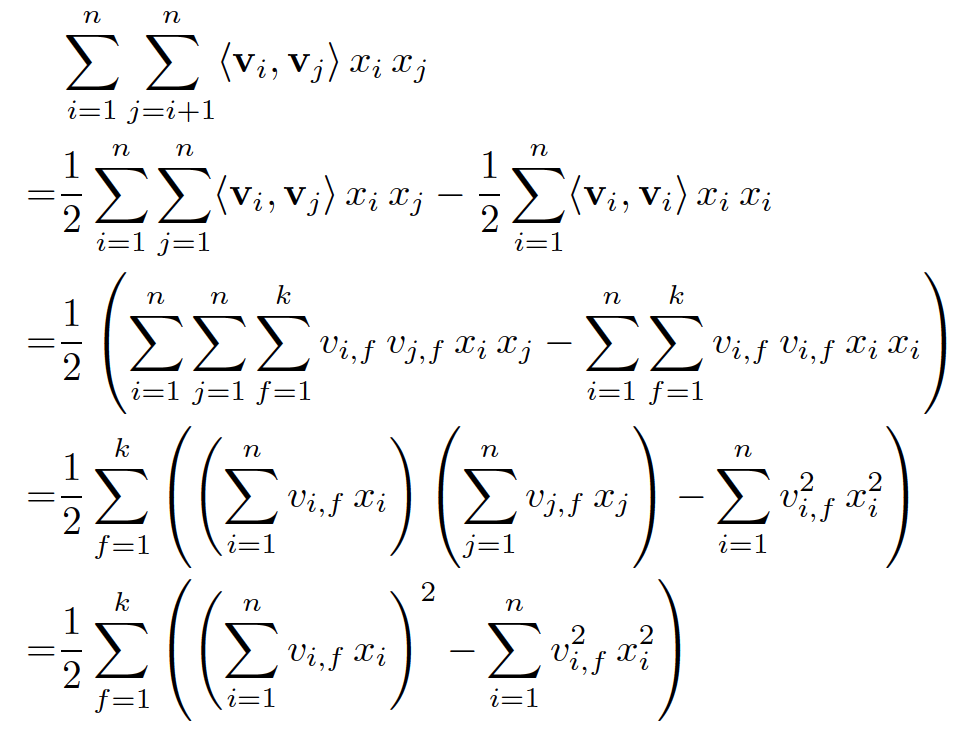
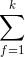 ,最终的时间复杂度是
,最终的时间复杂度是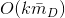 ,
,12.2.4 FM求解
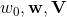 )可以在工程实现上高效地利用梯度下降算法(SGD、ALS等)来训练(即我们可以线性时间复杂度求出下面的
)可以在工程实现上高效地利用梯度下降算法(SGD、ALS等)来训练(即我们可以线性时间复杂度求出下面的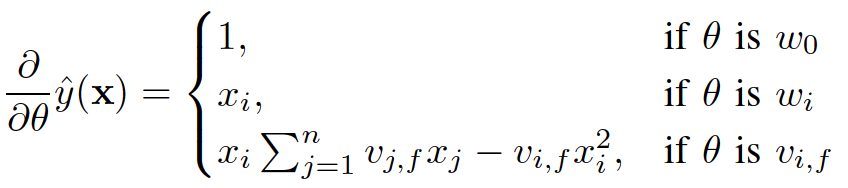
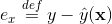 ,针对平方损失函数,具体的参数更新公式如下(未增加正则项,其他损失函数的迭代更新公式类似,也可以很容易推导出):
,针对平方损失函数,具体的参数更新公式如下(未增加正则项,其他损失函数的迭代更新公式类似,也可以很容易推导出):
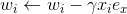

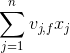 与i无关,因此可以事先计算出来(在做预测求
与i无关,因此可以事先计算出来(在做预测求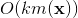 ,
, 12.2.5 FM进行排序的方法
回归问题(Regression)
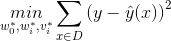
二元分类问题 (Binary Classification)
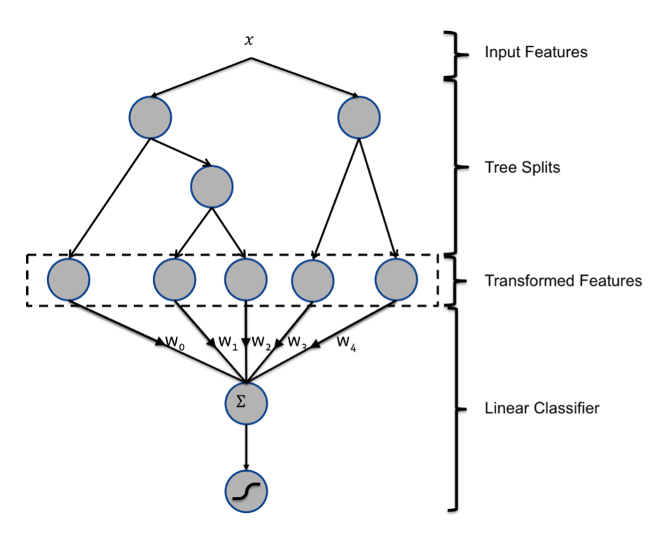
12.3 GBDT排序算法
12.3.1 GBDT的算法原理
 是第i棵决策树,其中
是第i棵决策树,其中

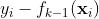 是当前模型
是当前模型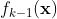 在样本点
在样本点 来拟合残差 。所有样本点上的残差之和就是整个训练样本在第k次迭代的残差(见下面公式)。
来拟合残差 。所有样本点上的残差之和就是整个训练样本在第k次迭代的残差(见下面公式)。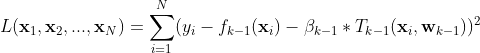
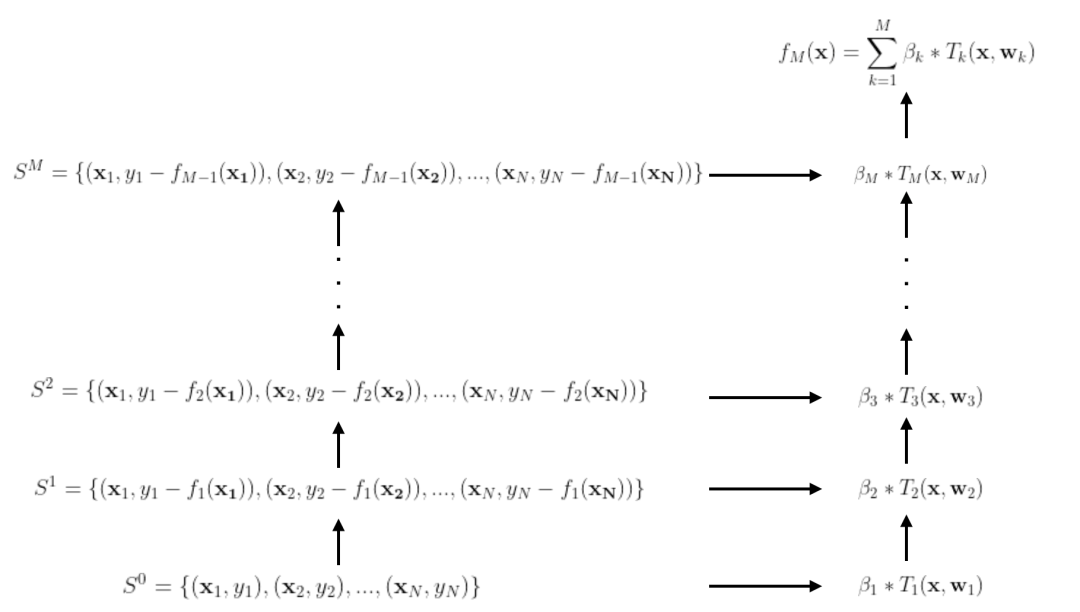
12.3.2 GBDT用于推荐排序