我们在第5章「推荐系统业务流程与架构」中讲到推荐系统一般会分为召回和排序两个阶段,召回可以看成是推荐前的初筛过程,排序是对初筛的结果进行精细打分的过程。我们在前面4章中介绍完了推荐系统召回算法相关的知识点,从本章开始,我们会花4章的篇幅来介绍排序算法。
10.1 什么是排序算法
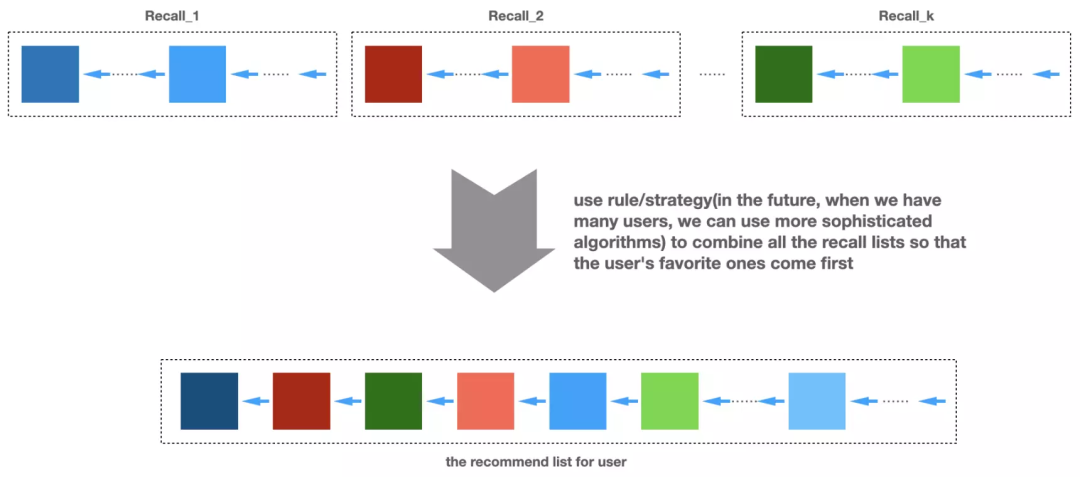
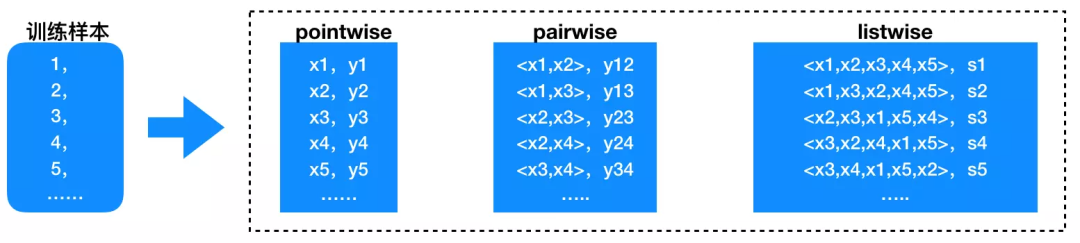
10.2 常用的排序算法介绍
10.2.1 规则策略排序算法
10.2.2 简单排序算法
10.2.3 高阶排序算法
10.3 排序算法的2种应用场景
10.3.1 个性化推荐场景下的排序
 ,这里 是用户, 是物品。那么样本集是所有这些用户 对物品 有操作行为的“用户物品对”构成的集合,即
,这里 是用户, 是物品。那么样本集是所有这些用户 对物品 有操作行为的“用户物品对”构成的集合,即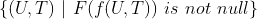 。的特征
。的特征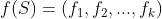 了,构建这5类特征的过程就是特征工程。下面图3以可视化的形式展示了每个样本按照5个维度的特征拼接获得的训练样本。
了,构建这5类特征的过程就是特征工程。下面图3以可视化的形式展示了每个样本按照5个维度的特征拼接获得的训练样本。 ,采用跟训练集中样本一样的方法构建这个待预测的“用户物品对”的特征,然后灌入训练好的排序模型获得最终的预测结果。
,采用跟训练集中样本一样的方法构建这个待预测的“用户物品对”的特征,然后灌入训练好的排序模型获得最终的预测结果。10.3.2 物品关联物品推荐场景下的排序
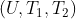 就可以作为一个样本。如果你的产品没有关联推荐,那么我们可以将用户在相近时间浏览的两个商品(比如用户搜索手机这个关键词,在搜索结果中同时浏览了iPhone13和华为P50)可以构成一个正样本对。之所以选择时间相近的,是考虑到用户在相近时间点兴趣点是一致的,这个一致性刚好是关联推荐需要挖掘出的关键信息。这里提一下,负样本对可以是当两个物品同时曝光时,用户点击了其中一个,另外一个没点击,那么这个样本对可以作为负样本对,或者通过随机选择两个物品来作为负样本对。三元组),但是我们这里讲的是非个性化的关联推荐,所以特征中不应该包含用户特征,同时行为特征中也不是单个用户的特征,而是群体相关的特征(比如的平均播放时长等),由于是两个物品
就可以作为一个样本。如果你的产品没有关联推荐,那么我们可以将用户在相近时间浏览的两个商品(比如用户搜索手机这个关键词,在搜索结果中同时浏览了iPhone13和华为P50)可以构成一个正样本对。之所以选择时间相近的,是考虑到用户在相近时间点兴趣点是一致的,这个一致性刚好是关联推荐需要挖掘出的关键信息。这里提一下,负样本对可以是当两个物品同时曝光时,用户点击了其中一个,另外一个没点击,那么这个样本对可以作为负样本对,或者通过随机选择两个物品来作为负样本对。三元组),但是我们这里讲的是非个性化的关联推荐,所以特征中不应该包含用户特征,同时行为特征中也不是单个用户的特征,而是群体相关的特征(比如的平均播放时长等),由于是两个物品